Vorhersagemodell für die Waldbrandgefahr in Deutschland
Waldbrand
Machine Learning
Lineare Regression
NDVI
Oberflächentemperatur
Niederschlag
Im zweiten Teil wird das Modell um weitere Eingabevariablen erweitert, darunter Niederschlagsmenge und Vegetationsindex. Anschließend wird die erweiterte Modellversion mit dem ursprünglichen Modell verglichen, um die Auswirkungen zusätzlicher Informationen auf die Vorhersagegenauigkeit zu untersuchen.
Autor:in
Zugehörigkeit
Sören Sparmann
Universität Paderborn
Veröffentlichungsdatum
22. Mai 2026
1 Multiple Lineare Regression
In Teil 1 haben wir festgestellt, dass die Oberflächentemperatur als alleinige Eingabevariable nicht ausreicht, um die Waldbrandgefahr zufriedenstellend genau vorherzusagen.
Deshalb erweitern wir das Modell – wie ursprünglich vorgesehen – um die zusätzlichen Variablen Vegetationsindex und Niederschlag.
2 Daten einlesen
Zunächst werden die historischen Daten erneut eingelesen, die als Grundlage für das Training des Vorhersagemodells dienen.
3 Erweiterte Modellannahme
Nun erweitern wir das Modell wie ursprünglich geplant, sodass auch die Variablen Vegetationsindex und Niederschlag in die Vorhersage einbezogen werden.
Da nun mehr als eine unabhängige Variable verwendet wird, handelt es sich um eine Multiple Lineare Regression (MLR).
Jede Eingabevariable \(x_i\) erhält dabei einen eigenen Koeffizienten \(a_i\), der den Einfluss dieser Variable auf die Vorhersage gewichtet. Das Modell besitzt somit insgesamt vier Parameter: \(a_1\), \(a_2\), \(a_3\) und \(b\).
Mathematisch ausgedrückt sieht das Modell wie folgt aus:
Teilen sie den Datensatz nun in Trainings- und Validierungsdaten auf.
Verwenden Sie die gleichen Parameter (random_state=42, test_size=0.25) wie zuvor, um die Vergleichbar sicher zu stellen.
(5 Minuten)
WarnungLösung
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)
6 Modell trainieren
Aufgabe 3
Trainieren Sie das Modell mit den Trainingsdaten.
(5 Minuten)
WarnungLösung
Wie zuvor wird das Modell mit der Methode .fit(X, y) an die Daten angepasst.
model.fit(X_train, y_train)
LinearRegression()
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
fit_intercept
True
copy_X
True
tol
1e-06
n_jobs
None
positive
False
7 Vorhersage machen
Aufgabe 4
Stelle dir vor, du verwendest das Modell in der Zukunft, um die Waldbrandgefahr vorherzusagen.
Im August 2028 wird folgende Messungen gemacht
Oberflächentemperatur: 35 C°
Vegetationsindex: 0.7
Niederschlag: 25 mm
Bestimme die zu erwartende Anzahl an Waldbränden!
(10 Minuten)
WarnungLösung
Mit der Methode .predict() können wir die Anzahl der Waldbrände vorhersagen. Dabei ist darauf zu achten, dass die Reihenfolge der Werte mit der Definition von X übereinstimmen.
model.predict([ [35, 0.7, 25]])
array([23.55662869])
8 Modell evaluieren
Aufgabe 5
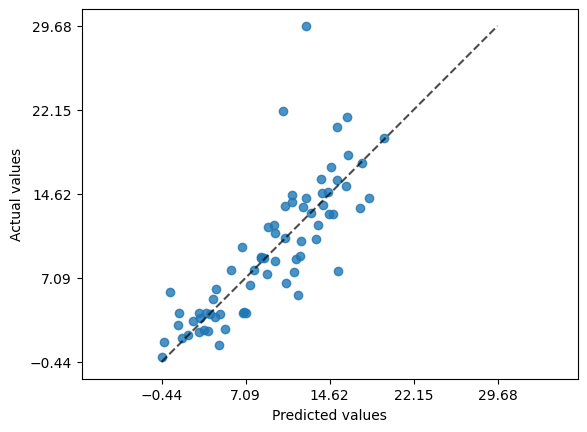
Evaluiere das Modell wie in Teil 1 gezeigt:
Erstelle ein Streudiagramm, das die vorhergesagten Werte den tatsächlichen gegenüberstellt.
Berechne den Score (\(R^2\)) des neuen Modells.
Hat sich die Güte des Modells durch das Hinzufügen der Variablen verbessert? Begründe!
(10 Minuten)
WarnungLösung
Der Score hat sich von \(0.57\) auf \(0.66\) verbessert.