{kind=link}
# Programmcode mit Kommentaren
px.scatter(df, x='precipitation', y='active_fires', trendline='ols')Einfache Lineare Regression (Teil 1)
Vorhersagemodell für die Waldbrandgefahr in Deutschland
Waldbrand
Machine Learning
Lineare Regression
NDVI
Oberflächentemperatur
Niederschlag
In diesem Teilmodul wird ein Vorhersagemodell entwickelt, das die Waldbrandgefahr in Deutschland einschätzt. Grundlage sind historische Satellitendaten, unter anderem zur Oberflächentemperatur, zur Niederschlagsmenge und zum Vegetationsindex. Zunächst wird ein einfaches lineares Regressionsmodell erstellt, das sich allein auf die Oberflächentemperatur stützt. Dabei werden grundlegende Konzepte des maschinellen Lernens vermittelt, insbesondere das Gradientenverfahren.
1 Waldbrände in Deutschland
Mit deutschlandweit 2397 Waldbränden ist 2022 ein deutlich überdurchschnittliches Waldbrandjahr im Vergleich zum mehrjährigen Mittel der Jahre 1993 bis 2021 (1.029 Waldbrände). Auch bezüglich der betroffenen Waldfläche ist das Jahr 2022 mit 3.058 Hektar - dies entspricht in etwa der Größe der Insel Borkum - ein deutlich überdurchschnittliches Jahr.
Quelle: Umweltbundesamt
Die Gefahr durch Waldbrände kann reduziert werden, indem Gebiete mit besonders hohem Waldbrandrisiko frühzeitig identifiziert werden. Dann können entsprechende vorbereitende Maßnahmen (Präventionsmaßnahmen) getroffen werden.
In diesem interaktiven Arbeitsblatt soll ein Modell für die Vorhersage des Waldbrandrisikos in Deutschland entwickelt werden. Das Modell wird mit historischen Daten trainiert, um zu lernen, wann das Waldbrandrisiko besonders hoch ist.

2 Daten einlesen
Zunächst werden die (historischen) Daten eingelesen, die für die Erstellung des Vorhersagemodells benötigt werden.
Bei den Daten handelt es sich um verschiedene Klimadaten aus Deutschland, die von Satelliten gemessen wurden.
Die Daten beinhalten
- die mittlere :Oberflächentemperatur (engl. Land Surface Temperature) in Grad Celsius (°C)
- den mittleren :Vegetationsindex (NDVI). Dabei handelt es sich um einen Wert zwischen 0 und 1, welcher angibt, wie “gesund” die Vegetation ist. Je höher der Wert, desto stärker belaubt ist die Vegetation.
- die mittlere kumulative :Niederschlagsmenge (engl. Precipitation) in Millimeter (mm) und
- die mittlere :Anzahl der Waldbrände (engl. Active Fires) in Deutschland pro 1000 \(m^2\).
Die Daten decken den Zeitraum von Juni 2000 bis Juni 2023 ab.
Die Daten liegen jeweils als Mittelwert für einen Monat vor.
Mit Hilfe der Funktion px.line() können die Daten in einem Liniendiagramm visualisiert werden.
TippTipp
Durch Doppelklick auf eine der Variablen kann diese einzeln betrachtet werden. Dies ist hilfreich, um z.B. die NDVI-Kurve besser erkennen zu können.
3 Zusammenhänge erkennen und beschreiben
Zunächst soll untersucht werden, ob Zusammenhänge zwischen den verschiedenen Variablen vorliegen. Dazu werden die Variablen paarweise in einem Streudiagramm (scatter plot) gegenübergestellt.
3.1 Oberflächentemperatur (Land Surface Temperature)
Beginnen wir mit der Oberflächentemperatur. Auf der x-Achse ist die gemessene Oberflächentemperatur dargestellt. Auf der y-Achse ist die dazugehörige Anzahl der Waldbrände im gleichen Zeitraum dargestellt.
Aufgabe 1
- Betrachte das Streudiagramm.
- Wie hängt die Oberflächentemperatur mit der Anzahl der Waldbrände zusammen?
- Formuliere eine Gesetzmäßigkeit: “Je höher … , desto … .”
(5 Minuten)
WarnungLösung
Aus der Darstellung ergibt sich folgender Zusammenhang:
Je höher die Oberflächentemperatur, desto höher die Anzahl der Waldbrände.
Der Zusammenhang is annähernd linear.
3.2 Niederschlag (Precipitation)
Betrachten wir nun die Niederschlagsmenge und wie diese sich auf die Waldbrandgefahr auswirkt.
Aufgabe 2
- Erstelle ein Streudiagramm (Scatter Plot), welches die Niederschlagsmenge (
precipitation) und die Anzahl der Waldbrände (active_fires) gegenüberstellt. - Orientiere dich dabei an dem vorherigen Beispiel für die Oberflächentemperatur.
- Wie hängt die Niederschlagsmenge mit der Anzahl der Waldbrände zusammen?
(10 Minuten)
WarnungLösung
Um die Niederschlagsmenge mit der Anzahl der Waldbrände zu vergleichen, muss der Wert für den Parameter x durch den Spaltennamen für die Niederschlagsmenge ersetzt werden.
Aus der Darstellung ergibt sich der folgende Zusammenhang:
Je höher die Niederschlagsmenge, desto niedriger die Anzahl der Waldbrände.
3.3 Vegetationsindex (NDVI)
Aufgabe 3
- Erstelle ein Streudiagramm (scatter plot), welches den Vegetationsindex (
ndvi) und die Anzahl der Waldbrände (active_fires) gegenüberstellt. - Wie hängt der Vegetationsindex mit der Anzahl der Waldbrände zusammen?
(10 Minuten)
WarnungLösung
Um den Vegetationsindex mit der Anzahl der Waldbrände zu vergleichen, muss lediglich der Parameter x durch den Spaltennamen des Vegetationsindex ersetzt werden.
Aus der Darstellung ergibt sich der folgende Zusammenhang:
Je höher der Vegetationsindex, desto höher die Waldbrandgefahr. Für sehr hohe Werte (gesunde Vegetation), nimmt die Waldbrandgefahr jedoch wieder ab. Daher besteht hier kein strikt linearer Zusammenhang.
px.scatter(
df,
x='ndvi',
y='active_fires',
trendline='ols' # Optional
)3.4 Visualisierung in Form eines 3D-Streudiagramms
Um den Zusammenhang zwischen den Variablen besser zu verstehen, eignet sich zusätzlich die Darstellung in einem dreidimensionalen Scatterplot. Jede Achse repräsentiert eine der Variablen Oberflächentemperatur, Vegetationsindex und Niederschlagsmenge. Die Farbe der Punkte entspricht der Anzahl der Waldbrände.
Aus der Darstellung lässt sich ein Areal erkennen, in dem die Anzahl der Waldbrände besonders hoch ist.
4 Vorhersagemodell für die Waldbrandgefahr
Basierend auf den Erkenntnissen soll nun ein Vorhersagemodell für die Waldbrandgefahr entwickelt werden.
Stelle dir vor, du möchtest die aktuelle Waldbrandgefahr vorhersagen. Mit Hilfe von Satellitendaten kannst du die aktuelle Oberflächentemperatur, den Vegetationsindex und den Niederschlag ermitteln.
Um nun aus diesen Daten eine Vorhersage abzuleiten, wird ein (mathematisches) Modell benötigt. Dieses erhält die entsprechenden Daten als Eingabe und berechnet daraus die Anzahl der zu erwartenden Waldbrände (siehe Abb. 1).
Wir verwenden dafür ein sogenanntes Lineares Modell (auch Lineare Regression genannt). Das ist im Wesentlichen nichts anderes als eine lineare Funktion, die du bereits aus dem Mathematikunterricht kennen:
\[y = f(x) = a \cdot x + b\]
Wenn wir geeignete Parameter a und b bestimmt haben, können wir damit eine Vorhersage für die Anzahl der Waldbrände y aus unseren Eingabedaten x berechnen.
Da die Variable Anzahl der Waldbrände von den Variablen Oberflächentemperatur, Vegetationsindex und Niederschlag abhängt, wird diese auch abhängige Variable (oder Zielvariable) genannt und die anderen Variablen unabhängige Variablen (Eingabevariablen).

5 Einfache Lineare Regression
Wir betrachten zunächst nur die Oberflächentemperatur als abhängige Variable und lassen die Variablen Niederschlag und Vegetationsindex vorerst außen vor.
5.1 Modellannahme
Wir haben zu Beginn gesehen, dass die Anzahl der Waldbrände mit steigender Oberflächentemperatur zunimmt.
Wir nehmen daher an, dass ein linearer Zusammenhang (lineare Funktion) zwischen der Oberflächentemperatur und der Anzahl der Waldbände besteht. Diesen können wir mathematisch wie folgt ausdrücken:
\[\text{active\_fires} = a \cdot \text{land\_surface\_temp} + b\]
- \(a\) (Steigung): Dieser Parameter zeigt, wie stark sich die Anzahl der Waldbrände ändert, wenn sich die Temperatur ändert. Ein positiver Wert von \(a\) bedeutet, dass höhere Temperaturen zu mehr Waldbränden führen, während ein negativer Wert darauf hinweist, dass höhere Temperaturen zu weniger Waldbränden führen.
- \(b\) (y-Achsenabschnitt): Dieser Parameter gibt die Grundrate der Waldbrände an, wenn die Temperatur null ist. Man kann ihn als Ausgangspunkt oder Basiswert der Waldbrände sehen.
Das Ziel ist es, die Parameter a und b so zu bestimmen, dass die daraus resultierende lineare Funktion, die Daten “bestmöglich” beschreibt (siehe Grafik).
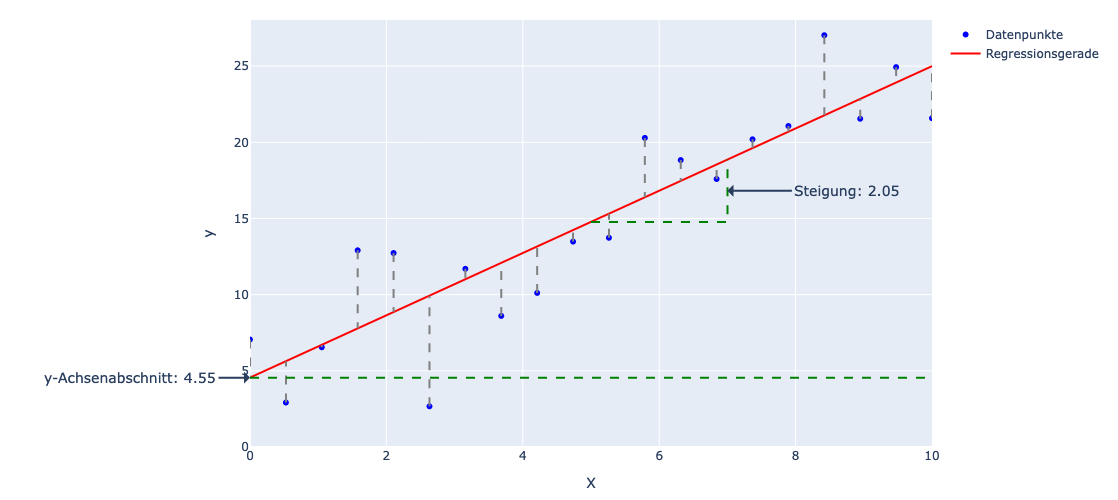
Zunächst erzeugen wir ein lineares Regressionsmodell. Dazu verwenden wir die Bibliothek sklearn, welche verschiedene Machine-Learning Modelle zur Verfügung stellt.
5.2 Unabhängige und Abhängige Variablen festlegen
Nun definieren wir die unabhängige(n) Variable(n) (Eingabe) und die abhängige Variable (Ausgabe) wie oben beschrieben. In unserem Fall soll die Anzahl der Waldbrände anhand der Oberflächentemperatur vorhergesagt werden. Symbolisch ausgedrückt:
\[\text{land\_surface\_temp} \rightarrow \text{active\_fires}\]
Daher ist die Variable Anzahl der Waldbände abhängig von der unabhängigen Variable Oberflächentemperatur.
Die abhängige Variable wird üblicherweise mit y bezeichnet. Die unabhängige Variable mit X.
TippHinweis
Da es in der Regel mehr als eine unabhängige Variable gibt, wird ein großes X anstelle eines kleinen x verwendet. Die Variablen werden daher in einer Liste ['variable_1', 'variable_2', '...'] aufgelistet. In diesem Fall gibt es jedoch nur eine unabhängige Variable (land_surface_temp).
6 Trainings- und Validierungsdaten
Bevor wir das Modell trainieren, teilen wir den Datensatz in zwei Teile auf: Trainingsdaten und Validierungsdaten. Die Trainingsdaten werden verwendet, um das Modell zu „lernen“, also die optimalen Parameter zu finden. Die Validierungsdaten dienen anschließend zur Bewertung, wie gut das Modell auf neue, bisher unbekannte Daten generalisiert.
Diese Aufteilung ist wichtig, um Überanpassung (Overfitting) zu vermeiden – das bedeutet, dass das Modell zwar die Trainingsdaten sehr gut vorhersagt, aber bei neuen Daten versagt.
Beispiel: Ein überangepasstes Modell könnte einfach die Zielwerte aus dem Training speichern und später bei gleichen Eingaben exakt wiedergeben. In den Trainingsdaten hätte es dann eine perfekte Vorhersage – aber sobald eine leicht andere Eingabe kommt (wie es bei echten Daten üblich ist), wäre die Vorhersage völlig unbrauchbar. Durch Validierungsdaten können wir prüfen, ob das Modell wirklich Zusammenhänge gelernt hat, oder nur auswendig gelernt hat.
Der Parameter random_state=42 sorgt dafür, dass die “zufällige” Aufteilung der Daten bei jeder Ausführung gleich ist. Das ist wichtig, damit wir bei der Modellentwicklung und Evaluation stets mit denselben Trainings- und Validierungsdaten arbeiten und vergleichbare Ergebnisse erhalten.
6.1 Modell trainieren
Wie bereits erwähnt, müssen wir nun die Parameter a und b so bestimmen, dass die daraus resultierende lineare Funktion möglichst gut an die Daten angepasst ist (engl. fit). Um die Güte der Anpassung messen zu können, benötigen wir ein sogenanntes Fehlermaß. In unserem Fall wählen wir die mittlere quadratische Abweichung (engl. Mean Squared Error).
Vereinfacht gesagt: Je weiter die Punkte im Mittel von der Geraden entfernt sind, desto höher ist der Mean Squared Error. Das Ziel ist es daher, den Mean Squared Error zu minimieren. Es handelt sich daher um ein sogenanntes Optimierungsproblem.
Aufgabe 4
Optimale Parameter bestimmen
- Verändere die Schieberegler für die Steigung und den y-Achsenabschnitt so, dass der Mean Squared Error minimal wird.
- Lese anschließend die beiden Parameter
aundbab.
(5 Minuten)
WarnungLösung
Die optimale Belegung der Parameter ist:
a = 0.48
b = 3.50
mse = 14.76.2 Gradientenverfahren
Das manuelle Anpassen der Parameter ist zeitaufwändig und unpräzise. Unser Modell verwendet zwar nur zwei Parameter, a und b, in komplexeren Modellen können jedoch weit mehr Parameter erforderlich sein.
Anstatt die Parameter manuell einzustellen, lernt unser Modell automatisch Schritt für Schritt die optimale Parameterkonfiguration aus den Daten. Dieser Prozess wird als maschinelles Lernen bezeichnet. Die Umsetzung variiert je nach verwendetem Lernverfahren, das Grundprinzip bleibt jedoch immer gleich.
Um das Modell zu trainieren, nutzen wir die Methode fit(X, y), wobei X die Eingabedaten und y die zugehörigen Zielwerte sind. Diese Methode passt die Parameter a und b automatisch an, um die optimale Konfiguration zu finden.
TippHinweis
Wir gehen an diesere Stelle nicht im Detail auf die zugrundeliegende Funktionsweise das Gradientenverfahrens ein. Die Idee dahinter ist den Wert der Ableitung (Gradient) der Fehlerfunktion (Mean-Squared-Error) für die jeweilige Paramterkombination zu bestimmen. Der Gradient zeigt dann an, in welche “Richtung” die Paramter angepasst werden müssen, um den Wert der Fehlerfunktiont zu reduzieren. Dieser Schritt wird solange wiederholt, bis keine nennenswerte Verbesserung mehr feststellbar ist.
Die folgende Animation zeigt die schrittweise Anpassung der Parameter.
6.3 Parameter ermitteln
Nachdem das Modell an die Daten angepasst wurde, können wir die Parameter a und b auslesen.
Aufgabe 5
- Angenommen es wurden 15 Grad Celsius Oberflächentemperatur gemessen.
- Berechnen Sie mit Hilfe der ermittelten Steigung und des y-Achsenabschnitts die zu erwartende Anzahl an Waldbränden.
(5 Minuten)
WarnungLösung
Die Anzahl der zu erwartenden Waldbrände ergibt sich aus der Funktion \(f\):
\[f(x) = a \cdot x + b\]
Um die Anzahl der zu erwartenden Waldbrände vorherzusagen, muss nun für x der Wert 15 eingesetzt werden.
\[f(15) = a \cdot 15 + b\]
a * 15 + bnp.float64(10.725801453435622)6.4 Vorhersage machen
Anschließend können wir mit Hilfe des trainierten Modells eine Vorhersage treffen.
Dazu verwenden wir die Methode predict(). Diese erwartet eine oder mehrere Eingaben im gleichen Format wie die Trainingsdaten – das heißt, mit derselben Anzahl und Reihenfolge der Variablen. Als Ausgabe erhalten wir eine Vorhersage für die Zielgröße, in diesem Fall die zu erwartende Anzahl an Waldbränden.
Beispiel: Angenommen es wurden 32 Grad Oberflächentemperatur gemessen. Unser Modell liefert folgende Anzahl zu erwartender Waldbrände:
Um unser Modell im Anschluss zu evaluieren, erstellen wir eine Vorhersage für die Validierungsdaten df_val. Dann vergleichen wir die vorhergesagten Werte mit den tatsächlichen Beobachtungen, um zu beurteilen, wie gut das Modell generalisiert.
HinweisHinweis
Das Modell erwartet als Eingabe immer eine Liste von Messungen. Jede Messung besteht wiederum aus einer Liste von Messwerten (ein Messwert für jede unabhängige Variable). Daraus ergibt sich die Schreibweise mit doppelten Klammern [[32]].
6.5 Modell evaluieren
Um das Modell zu evaluieren, vergleichen wir die Vorhersagen des Modells mit den tatsächlich gemessenen Werten.
Dazu erstellen wir ein Streudiagramm. Auf der y-Achse werden die tatsächlich gemessenen Werte dargestellt, während die x-Achse die vorhergesagten Werte zeigt.
Eine gute Vorhersage bedeutet, dass die vorhergesagten Werte den tatsächlichen Werten weitgehend entsprechen. Das heißt, die x- und y-Koordinaten eines Punktes sind nahezu identisch, und der Punkt liegt nahe an der Geraden \(f(x) = x\). Befinden sich die Punkte jedoch weit entfernt von dieser Geraden, deutet das darauf hin, dass das Vorhersagemodell die Daten nicht zuverlässig abbildet.
HinweisHinweis
Die Gerade wird auch Identitätsgerade genannt.
Mit der Methode score(X, y) lässt sich ein Maß für die Güte des Modells bestimmen. Dabei handelt es sich um das sogenannte Bestimmtheitsmaß \(R^2\), welches angibt, wie gut das Modell die Daten beschreibt.
Ein Wert von 1 würde bedeuten, dass das Modell die Daten perfekt beschreibt, d.h. dass alle Punkte genau auf der Geraden liegen. Ein Wert von 0 bedeutet, dass kein linearer Zusammenhang besteht.
Es gilt: Je höher der Score, desto besser beschreibt das Modell die zugrunde liegenden Daten.
HinweisFormel
Das Bestimmtheitsmaß (R^2) wird definiert als
\[R^2 \;=\; 1 - \frac{\sum_{i=1}^{n} (y_i - \hat{y}_i)^2}{\sum_{i=1}^{n} (y_i - \bar{y})^2}\]
wobei
- \(y_i\) = beobachtete Werte,
- \(\hat{y}_i\) = durch das Modell vorhergesagte Werte,
- \(\bar{y}\) = Mittelwert der beobachteten Werte,
- \(n\) = Anzahl der Beobachtungen.
Der ermittelte Wert deutet darauf hin, dass zwar ein linearer Zusammenhang besteht, dieser jedoch nicht ausreicht, um die Komplexität der Daten vollständig zu erfassen. Das Modell erklärt also nur einen Teil der Variabilität in den Beobachtungen.
Um die Vorhersagegenauigkeit zu verbessern, erweitern wir im nächsten Teil das lineare Modell um zusätzliche Eingabevariablen.
7 Zusammenfassung
In diesem Notebook hast du gelernt, wie du:
- Daten aus einer CSV-Datei mit
read_csv()einlesen und in einem DataFrame speichern kannst, - die Daten explorierst und mit Diagrammen wie
px.line()(Liniendiagramm) undpx.scatter()(Streudiagramm) visualisierst, - die Beziehung zwischen zwei Variablen – hier Oberflächentemperatur und Anzahl aktiver Brände – untersuchst,
- ein einfaches lineares Regressionsmodell mit
LinearRegression()aussklearnaufbaust, - das Modell trainierst (fit) und Vorhersagen machst (predict),
- die Modellgüte mit Metriken wie dem Bestimmtheitsmaß (R²) einschätzt,
- den Einfluss der Oberflächentemperatur auf die Waldbrandgefahr interpretierst.
Wiederverwendung
Zitat
Mit BibTeX zitieren:
@online{sparmann2026,
author = {Sparmann, Sören},
title = {Einfache Lineare Regression (Teil 1)},
date = {2026-05-22},
url = {https://material.cdec.io/modul_2/submodules/02_waldbrand/01_einfache_lineare_regression.html},
langid = {de}
}
Bitte zitieren Sie diese Arbeit als:
Sparmann, Sören. 2026. “Einfache Lineare Regression (Teil
1).” May 22. https://material.cdec.io/modul_2/submodules/02_waldbrand/01_einfache_lineare_regression.html.